Update: my Syntiant Core 2 presentation bested Samsung and Qualcomm to win Best Product at TinyML!
\/Original Blog Post\/
One of my great professional privileges when founding Syntiant's machine learning stack has been collaborating with a team of electrical engineers in the design, development, verification, and shipping of an ultra-power efficient tensor computation core for Syntiant products. Although I resisted interviewing with Syntiant because I am not an electrical engineer, the hardware collaboration process we have developed through now two "Syntiant Cores" has borne fruit after three years of trading between machine learning requirements and silicon capabilities.
I am quite proud of the silicon architecture we developed together and impressed with the capabilities of my electrical engineering colleagues. Never did they say to me "it can't be done." Below is a marketing post I wrote for machine learning engineers as an introduction of Syntiant's now two cores.

The Growing Syntiant Core Family
With the release of the NDP120, Syntiant's line of Neural Decision Processors (NDPs) now include two tensor computation cores providing superior energy efficiencies in neural computation. The "Syntiant Core 2" builds on the lessons learned in the field from millions of shipped Syntiant Core 1 found in the NDP100 line of chips. While the Syntiant Core 1 requires the absolute lowest energy running at 140 uW for audio key-word-spotting applications, the Syntiant Core 2 provides a flexible neural network runtime with up to 25x the processing power of the Syntiant Core 1. Here we cover the details of both Syntiant cores to explore the problems solvable by the cores and the modelling effort required to put them into the field.

Figure 1a. The SC1 navigating a forest

Figure 1b. The SC2 flying over "competing" edge processors

Figure 1c. A charged GPU shortly after draining the nearest star for power
Syntiant Core 2
Edge neural network chips are notoriously difficult training targets. The combination of limited neural architecture support, high compression factors, and distributional shift between training data and the real world can delay product shipments for months or even years. When designing the Syntiant Core, Syntiant sought to alleviate these challenges and enable more and better edge neural solutions on tight production timelines.
As a first principle, the SC2's highly-optimized tensor-based memory subsystem is designed to avoid inefficiencies in stored program architectures. Each layer independently controls its parameter, input, and output tensors consistent with graph-based execution and runs without repeated memory addressing overhead. The graph-based execution provides full control for running concurrent independent networks, or even swapping network configurations depending on operating conditions. When building on top of the SC2 execution engine, many always-on problem domains become feasible because you don't pay for the inefficiencies of a microcontroller. The benefits of specialization are manifest not only in power efficiency, but also in throughput.
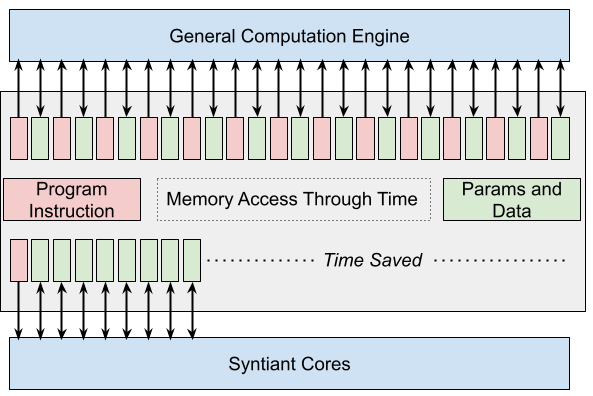
Figure 2. Stored program architectures have their programs stored in memory and are loaded at runtime. Consequently, the runtime cannot make many program assumptions that optimize for throughput and energy. In contrast, the SC2 has all the neural network programming baked into the silicon.
The SC2 packs 32 parallel multiply and accumulate (MAC) paths operating at up to 100 MHz. This packs enough solution power to continuously process audio signal paths, detect objects in images, and monitor an accelerometer for motion events. These inputs can be concatenated for single models that jointly understand audio, image, and motion of the device's environment, or cascaded into multi-modal conditional workloads. With the ability to grow through time, the SC2 can serve as the basis for multi-product development programs that solve new deep learning problems with each generation.
While the SC2 has the throughput necessary for many problem domains, can it express proven and forthcoming neural architectures that solve tasks at production environment levels?
Problem domains
- Far field wakeword
- Multi-modal sensor fusion
- Speech enhancement
- Active noise cancellation
- Speech interfaces
- Acoustic event detection
- Image recognition
- Gesture detection
- Anomaly detection
- Passive infrared event detection
After spending months or years learning how to train specific architectures to production standards, deep learning engineers do not want to throw out their playbook and start with an architecture dictated by silicon. With the SC2, the deep learning engineers can select their neural architecture. Syntiant cores are highly-optimized for tensor computation and can run many architectures end to end without needing to involve any of the stored program components of the NDPs. For more exotic architectures, the SC2 shares execution with the on-chip digital signal processor (DSP). So the SC2 can, for example, compute a large convolutional kernel in parallel while the DSP runs a leaky ReLu activation. Port a trained network or move flexibly through the neural design space.
While supporting so many different architectures makes a wide variety of solutions possible, it is also important that these architectures be trainable from the data and tools that are already well known by deep learning engineers.
All major frameworks and interchange formats port to the SC2 runtime. Whether the SC2 runs inference end to end, or the DSP is involved, Syntiant's tools ship with a bit-exact GPU-accelerated runtime for evaluating performance. Deep learning engineers do not need to leave the cloud to evaluate on the edge. You can test against terabytes of data without maxing out your cloud budgets.
Neural Architecture Support
- Native Layers
- Convolutions: Standard, Upsampling, Depthwise
- Pooling: Average, Max
- Fully connected: Dense
- Operations: Multiplication, addition
- Compositional Layers (multiple native)
- LSTM
- GRU
- Native Activations
- ReLu
- TanH
- Sigmoid
- Linear
- Architecture Types
- Convolutions with striding and dilation
- Ensembles and cascades
- Attention
- Skip connections
- Branching/concatenating layers
- And more!
Although support for "no compromises" neural design is an important feature of the SC2, it is also possible to get closer to the metal with design tools supplied by Syntiant. The complete power, latency, memory, and parameter requirements of different neural architectures can be scored programmatically and hooked into large scale hardware-aware hyperparameter searches. Most hyperparameter searches will find task performance is stronger with larger architectures, but these architectures may be so large that they need to be compressed.
The evolving practice of neural compression is natively supported by the SC2. Architectures support mixtures of 1, 2, 4, and 8 bit weights with higher precision bias terms. For the most challenging tasks, the SC2 supports high precision modes including 16 bit inputs and outputs. Heavy quantization is optional. Quantize when wanted, but not just because an edge processor requires it.
Framework Support
- Native Support
- Keras Floating Point
- Keras Fixed Point (bit-exact for chip)
- Easy Sourcing
- Keras
- Tensorflow
- PyTorch
- MXNet
- h5
- ONNX
- Native Activations
- ReLu
- TanH
- Sigmoid
- Linear
While all these features are general to any neural network solution, the SC2 includes task-specific optimizations that exploit the properties of time series and sparsity to increase throughput and decrease energy consumption.
Neural Compression Support
- Mix 1, 2, 4, and 8 bit precision layers
- Bias term is always 16 bits
- Switch between 8 and 16 bit activations
- Modify activation scales to minimize quantization error
- Prune activations
These optimizations run "under the hood," meaning the SC2 leverages these optimizations without the deep learning engineer needing to tune or condition them at training time. The solution just works better.
Task-Specific Optimizations
- Avoid recomputing convolutional kernels in time series with caching
- Automatically skip computations of sparse inputs
Syntiant Core 1
Perfection is achieved, not when there is nothing more to add, but when there is nothing left to take away. - Antoine de Saint-Exupéry
While the SC2 is multi-featured and flexible, the SC1 is always a five layer fully connected network of 4 bit weights and biases.
This network scale is scoped to meet near field wakeword requirements (e.g., "Alexa" and "OK Google") via 8 parallel MACs operating at 16 MHz. Many single-network tasks fit within this network size, including many audio processing tasks that operate on extracted audio features.
Example Problem Domains
- Near field wakeword and small vocabulary speech interfaces
- Acoustic event detection
- Sensor event detection
- Passive infrared event detection
How should you choose between the Syntiant cores? Thankfully, you don't need to choose between the SC1 and 2 before beginning deep learning engineering. The same tools developed for the SC2 have all been backported to the SC1, so if you find your task is solvable with a smaller neural network, you can switch to the SC1 in Syntiant's tools with just a single line of code. Start with the SC1 and scale up if needed, or start with the SC2 and scale down when the solution more than exceeds expectations. In either event, deep learning solutions now have room to grow.
Note: This post has been updated from the version originally posted to update the star wars graphic, add a new graphic illustrating stored program architectures, and clarified a few points.